
Meta AI Releases New Quantized versions of Llama 3.2 (1B & 3B) models with 2-4x increases in inference Speed and 56% Reduction in Model Size.
Table of contents
Open Table of contents
Introduction
Meta AI has recently released new quantized versions of the Llama 3.2 (1B & 3B) models. These quantized models are designed to be more efficient and lightweight, with a 56% reduction in model size and 2-4x increases in inference speed compared to the original BF16 models.
Key takeaways
- As Meta has access to computing resources, training data, full evaluations and safety, they are uniquely positioned to provide quantized models.
- These are their first quantized models in the Llama category. These instruction-tuned models apply the same quality and safety requirements as the original 1B and 3B models.
- These models are 56% smaller and 2-4x faster than the original BF16 models.
- Techniques used to quantizing Llama 3.2 1B and 3B models:
- Quantization-Aware Training with LoRA adaptors - This technique prioritizes accuracy.
- SpinQuant - This is a state-of-the-art post-training quantization method that prioritizes portability.
- Inference using both quantization techniques is supported in Llama Stack reference implementation via PyTorch’s ExecuTorch framework
- These models are available on Qualcomm and MediaTek SoCs with Arm CPUs.
Accuracy
Llama-3.2 1B QLoRA delivers competitive accuracy to Llama-3.2 1B BF16 while improving the inference speed significantly on Android phones.
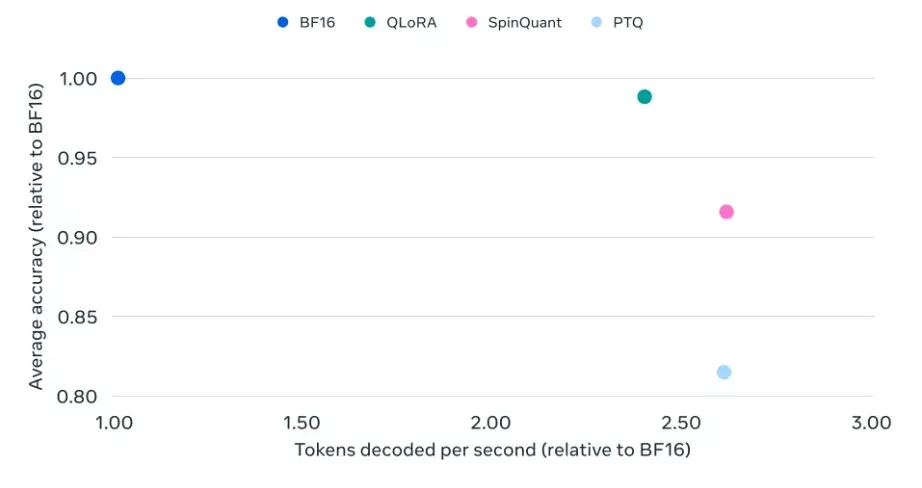
Similar improvements were observed for the 3B model.
Safety
As these models are small and can be executed on mobile devices, they can run offline and the data never leaves the device. This ensures user privacy and data security.
As these models execute locally it opens up numerous possibilities for the on-device AI capabilities.
Availability
The models can be downloaded from Hugging Face or Llama Website
Conclusion
The release of the quantized versions of Llama 3.2 (1B & 3B) models is a significant milestone for Meta AI. These models are more efficient and lightweight, with a 56% reduction in model size and 2-4x increases in inference speed compared to the original BF16 models. This will enable developers to deploy AI models more easily on resource-constrained devices, opening up new possibilities for AI applications in various industries.
Read more about the release here