
OmniParser is a compact screen parsing module that can convert UI screenshots into structured elements.
Table of contents
Open Table of contents
Introduction
Recent advancements in large vision-language models (VLMs), such as GPT-4V and GPT-4o, have demonstrated considerable promise in driving intelligent agent systems that operate within user interfaces (UI).
Limiting factor in screen parsing
When using only vision input to act as general agents across diverse operating systems, one of the primary limiting factors is the absence of a robust technique for screen parsing. The screen parsing should be capable of the following points.
- Reliably identifying interactable icons within the user interface
- Understanding the semantics of various elements in a screenshot and accurately associating the intended action with the corresponding region on the screen.
OmniParser
OmniParser is a compact screen parsing module released by Microsoft. The main features of the modules are:
- Can convert UI screenshots into structured elements.
- Can be used with various models to create agents capable of taking action on UIs.
When used with GPT-4V, it significantly improves the agent’s capability to generate precisely grounded actions for interface regions.
Creation of OmniParser
Curation of Specialised Datasets
The development of OmniParser began with the creation of two datasets
Interactable icon detection dataset
This dataset is curated from popular web pages and annotated to highlight clickable and actionable regions
Icon description dataset
This dataset is designed to associate each UI element with its corresponding function. This dataset serves as a key component for training models to understand the semantics of detected elements.
Fine-Tuning Detection and Captioning Models
OmniParser leverages two complementary models
Detection model
Fine-tuned on the interactable icon dataset which reliably identifies actionable regions within a screenshot
Captioning models
They are trained on the icon description dataset, which extracts the functional semantics of the detected elements, generating a contextually accurate description of their intended actions.
Benchmark Performance
Average Performance Across Benchmarks
The performance measured across different benchmarks is promising.
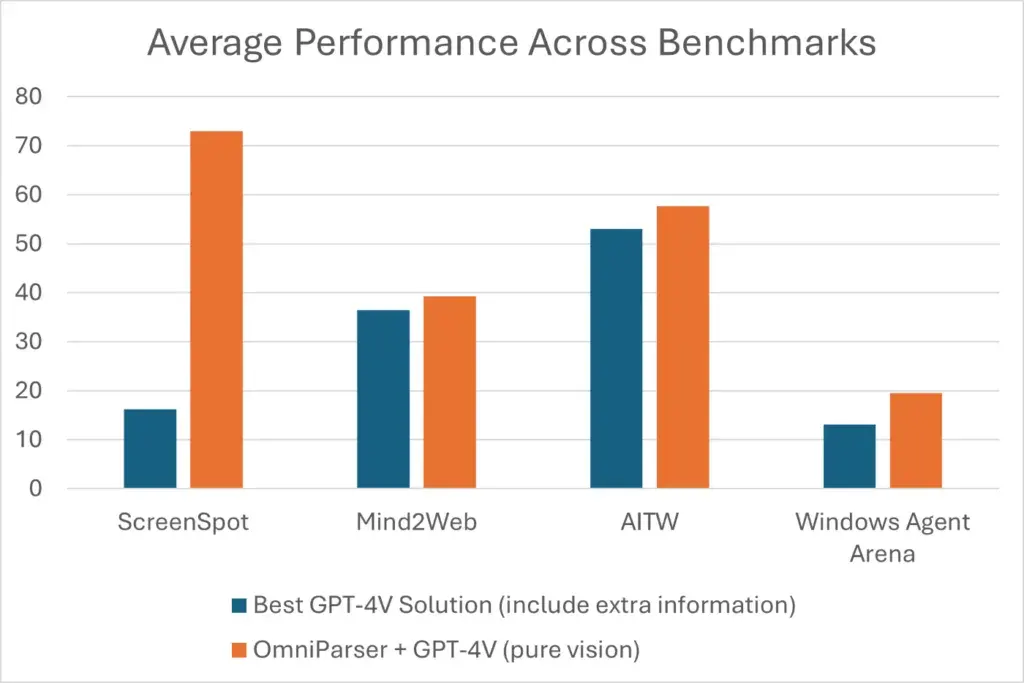
- On most of the benchmarks like ScreenSpot, Mind2Web, AITW and Windows Agent Arena OmniParser + GPT-4V achieves better performance compared to GPT-4V agent that uses extra information extracted from HTML
OmniParser with Other vision language models

- Above is the chart for the result of different models with OmniParser and its performance relative to other plugins for vision parsing
Use Cases
As OmniParser is capable of identifying screen regions with actionable items it opens up possibilities for accurate and fast automation with different use cases.
Automatic Test Case extractions
OmniParser can be used to extract test cases from UI screenshots and generate test scripts for automation testing.
Automate UI flows for repetitive tasks faster
OmniParser can be used to automate repetitive tasks by identifying the regions in the UI and generating the scripts to automate the tasks.
Identify optimal user flows for navigation
OmniParser can be used to identify the optimal user flows for navigation in the UI and suggest improvements. Along with that, it can also be used to identify the regions where the user spends more time and suggest improvements.
Conclusion
OmniParser is a compact screen parsing module that can convert UI screenshots into structured elements. It can be used with a variety of models to create agents capable of taking action on UIs. When used with GPT-4V, it significantly improves the agent’s capability to generate precisely grounded actions for interface regions. The performance measured across different benchmarks is promising. On most of the benchmarks like ScreenSpot, Mind2Web, AITW and Windows Agent Arena OmniParser + GPT-4V achieves better performance compared to GPT-4V agent that uses extra information extracted from HTML. OmniParser can be used in various use cases like automatic test case extractions, automating UI flows for repetitive tasks faster and identifying optimal user flows for navigation. It opens up possibilities for accurate and fast automation with different use cases.